This is an expanded version of the paper "A prototype browser and portal for data grids" in the proceedings for the ADASS XI conference (October 2001), as published by the Astronomical Society of the Pacific. The printed paper was severely restricted in length and we could not include many of the details of our system. These web pages contain the original paper as presented (as a poster and live demonstration) at ADASS XI.
In a compute grid:
In a data grid:
A compute grid is most useful when a there are many raw data to be reduced and their processing must be shared between sites. A data grid is more useful when reduced data already exist at data centres and must be exploited by many users at remote sites.
In this emerging era of large astronomical surveys prepared by specialist teams, a data grid is of more immediate use than a generalised compute grid. The data grid is the foundation of the much-desired Virtual Observatory. The aim of the Astrogrid project is to provide a data grid to the astronomical community.
The science and technical requirements for Astrogrid have not yet been made formal, but these general goals for the grid have been suggested:
Astrogrid infrastructure shall provide these services to application programmes:
- Ability to store data 'on the grid' without needing to specify details of the means of storage, or the location of storage or the topography of the grid.
- Ability to discover the presence and nature of data previously stored, without prior knowledge of the means of storage, location of storage or topography of the grid.
- Ability to operate on the discovered data in situ, or to operate on an in-situ copy of the discovered data, and to store the results of the operation 'on the grid', as above.
- Ability to copy selected discovered data to the client computer.
This suggests three main problems that must be solved in providing a solution:
The selection/location problem is specific to data grids (Compute grids have a parallel problem of finding and choosing processor nodes, but the details are very different.) The compute-grid work will not provide a ready-made solution to this. Furthermore, the best solution will involve metadata specific to the scientific domain of application.
Data are payload: the pixel values in an image file, say, have meaning regardless of the file format. Metadata make that meaning apparent to readers of the file. For example, in a FITS file, the header --- metadata --- defines the meaning of the image array or table. The usability of a data item is fixed by the quality of its metadata.
In a query of a single archive, the result is a data extract that can be presented to the enquirer immediately, as a direct response to the query. The data-grid is supposed to apply a given query (e.g. "tell me of all known stellar objects within 20 arcminutes of the core of M87") to all the data on the grid. On a well-populated data-grid, the number of data-products relevant to a given query can be very large, and it is typically not useful to return all the data of the result in one go. Instead, the user needs to see the descriptive metadata for the results and then to select particular groups of results for further attention. We call this grouping of metadata for search results a coverage report, and we require a format to express it.
It is now becoming common to express metadata in XML, and XML naturally generates hierarchies of nested objects. In a data-grid built to give access to data-centres, the following seems to be a relevant hierarchy.
E.g., for a given data-set, there may be both an image and an object catalogue.
Using these definitions, a coverage report can be built up as a list of data- service objects (i.e. the set of services queried) each containing zero or more data-set objects (i.e. the sub-set of data-sets in the service that are relevant to the query); the data-set objects in turn each contain one or more data-product objects (i.e. the actual files of results that the user can obtain).
We built a minimal data-grid specifically to experiment with aspects of the selection/location problem. We have deferred questions of authentication by using public data-services; we have avoided the risks of new data-transport software by using proven technology from the WWW.
We seek answer to these questions:
We are also keen to develop the experimental grid to a point where it can be used in a beta test. We believe that many of the science requirements for Astrogrid can only become known as a result of beta testing a prototype. Since the prototype grid has proved successful, we have the option of using it as a tool to access and test new data services being developed by the Astrogrid project. In particular, the grid portal may be a useful way to test the federations of databases planned by Astrogrid.
The software discussed here is not the intended product of Astrogrid; it is not even likely to be evolved into the final product. We expect that the current grid and portal will be taken out of service at the end of the experiment and replaced by Astrogrid's standard software.
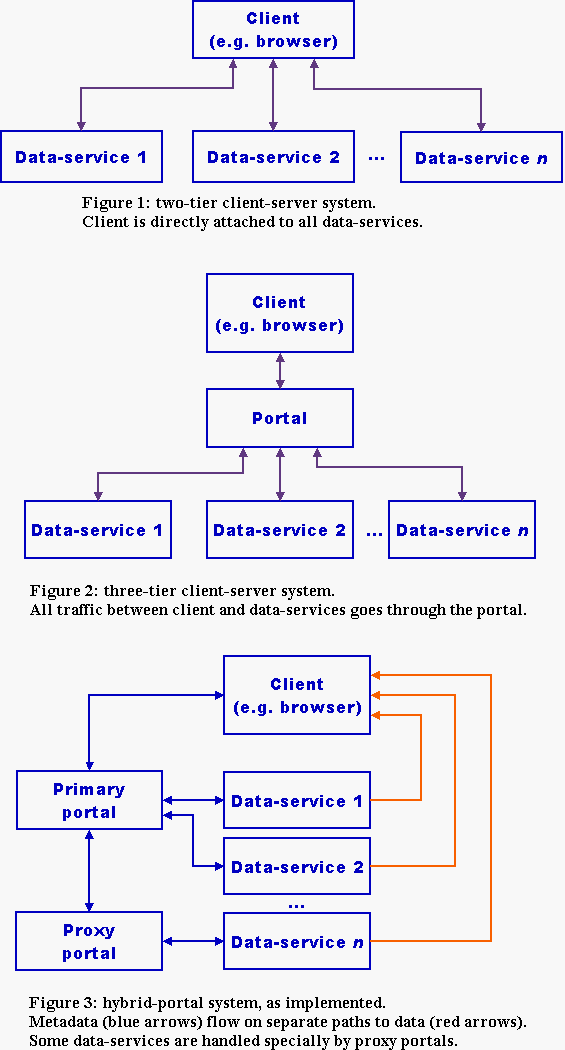
We considered three architectures for the experiment: a two-tier client-server system; a three-tier system using a portal in the central tier; and a hybrid of the two
In the two-tier model (Figure 1), the client software is linked directly to each data-service. This is straightforward, but makes problems for the client programming:
This means that a new release of client software is needed each time a data service is added or a service is extended. This architecture cannot serve a dynamic grid.
In the pure three-tier model (Figure 2), all data and metadata are passed to the client via the portal. This means that the portal can adapt and standardise the metadata sent to the client, and the client code can be simpler. The portal keeps the index of services and the services can be extended, moved or rearranged without changing the client software. However, all data sent for visualisation or other client-side processing have to be moved twice, once to the portal and again to the client. This compromises the browsing performance.
In the hybrid model (Figure 3), the inquiries from the client and the metadata returned by the data-services go via a portal. The actual data downloaded to the client go directly from the data-centre to the client, bypassing the portal; the metadata sent from the portal to the client tell the latter exactly how to fetch the data: i.e. the metadata included a full URI that obtains the selected data product according to the query constraints. The hybrid model is, of course, the one used in general search-engines on the WWW.
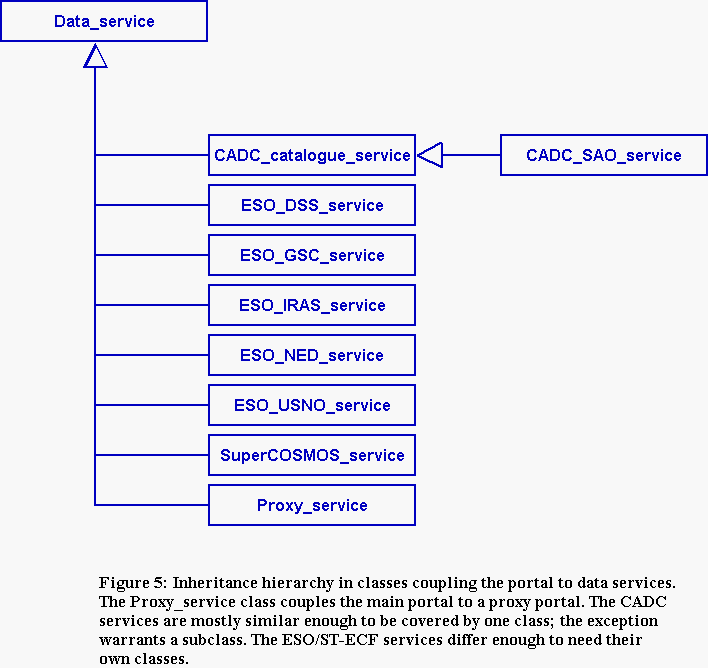
Our portal is written as a CGI application in Perl. The design is object oriented, with components handling particular data-services implemented as separate classes (Figure 5). The portal itself is only 37 lines of Perl, the application classes are ~700 lines of Perl and the whole is supported by ~2,000 lines of Perl and C written by CASU plus several standard modules from CPAN.
Each query makes one call to the portal CGI and receives in return one coverage report in XML. The portal forwards the query to each of the data- services that it knows by invoking a CGI programme at each service. The portal customises the query to suit each data-service by altering the CGI parameters to the syntax used by that service. Queries to data-services are run in parallel to save time. Figure 4 shows the data-services used. Some data-services have an on-line index for their data-sets. The INT Wide- Field Survey, e.g., has one data-set per CCD observation and an index of observations is kept in Cambridge. The portal can get a coverage report from this without retrieving any actual data.
Other data-services have only one data set. In the case of object catalogues, the portal then has to request data output to determine coverage. The portal requests a single row of output from the data-service: if it gets one, then it makes a positive entry in the coverage report; if not, it makes a negative entry. Note that the portal is generating the metadata for the report. Where a data service is hosted at an Astrogrid site, a proxy portal can be used. This is a an application that presents the same CGI interface to the main portal that the latter presents to the client, but which is directly connected to one data-service. The proxy portal returns a complete coverage report in XML concerned only with its associated service, and the main portal collates these. The intimate coupling between the proxy portal and the data-service allows finer control of the generated metadata.
The grid has two proxy portals at present: one for the INT WFS and one for the FIRST object-catalogues; both of these data-services are hosted at CASU. The previously-available interfaces to FIRST lacked a suitable interface for our grid and we found it easier to host a copy of the catalogue than to parse the output from FIRST's WWW interface.
Our single client application is a browser for interactive use of the grid. Other clients could easily be built if the experiment was extended.
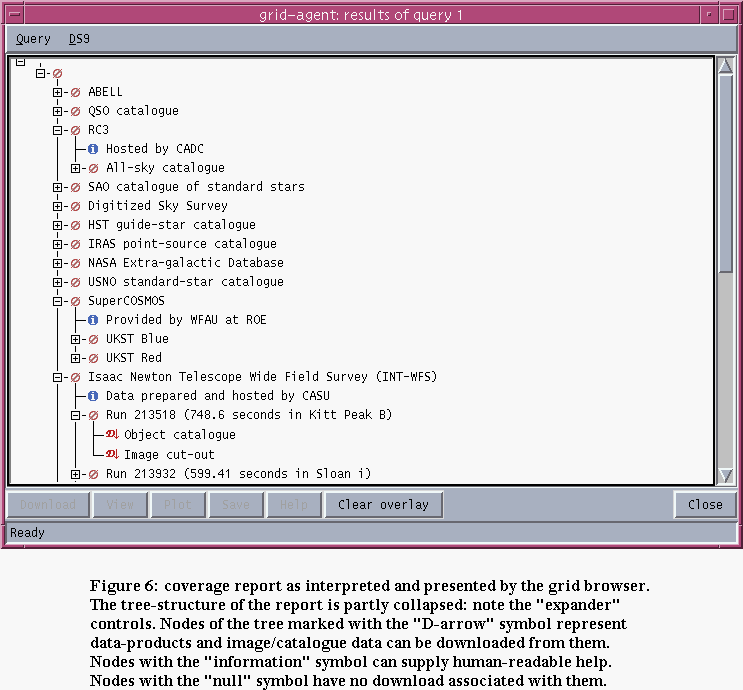
We considered using a conventional web-browser and writing the application as a Java applet. This approach we rejected because of the difficulty in operating a worthwhile image-display in a simple Java programme. Instead, we built the client as a GUI programme in Perl/Tk, using many modules from CPAN. The client is based around a window that visualises a coverage report as a tree structure (Figure 6). Image display is delegated to SAOimage/DS9 (using the XPA interface ) and display of HTML is delegated to an external copy of Netscape navigator. Display of catalogue extracts as tables is handled inside our programme.
The browser is ~3,000 lines of Perl excluding code reused from CPAN.
The FIRST survey is a useful example of how inappropriate metadata make it hard to incorporate a data resource into the grid.
FIRST has two on-line interfaces: an image-server and a catalogue server. The image server emits FITS files and we had no difficulty in using it on the grid. The catalogue server emits HTML reports, which are very hard to use in a grid.
In general, HTML output is an unsuitable format for catalogues on a grid. HTML is metadata for WWW browsers but is concerned entirely with how a page should be rendered as graphics; it says nothing about how the output should be parsed to recover the data. While the HTML output from FIRST is fine for the WWW (and we make no criticism of the FIRST project!) the metadata are inappropriate for the grid.
This is a common problem: the majority of catalogue servers today emit HTML only. By comparison, the servers at CADC and ESO/ST-ECF that emit TSV catalogues directly (i.e. the data-services that provide fewer metadata) are much better suited to the grid.
It would have been possible to build a parser (to run at the portal site) to parse the HTML output from FIRST and retain only the catalogue data in TSV format. However, this would be likely to break in subtle ways if the data-service ever changed any details of their HTML. Instead we judged it easier to copy the FIRST catalogue (which is only ~80MB in ASCII form) to a server in CASU and access it there with an interface of our choice.
Clearly, this approach cannot be used for all catalogues, especially the large ones. Instead, some grid-worthy interface needs to be added each catalogue at its own data-centre, and this must be done without requiring excessive work by the data-centre staff. As part of the portal experiment, we intend to produce a "proxy-portal home-build kit" whereby a proxy portal can easily be added to any data-service that uses a relational database for its index. The prototype components for this kit are already in use at CASU.
Since the coverage report is a private communication between the portal and the client, we invented a minimal language for it using XML. The language expresses a hierarchy of objects: data-products contained within data-sets contained within data-services contained within an overall results structure. There are also "provenance" objects to describe the origin of the data at the same level of the hierarchy, and "apology" objects to indicate positively where no data-products are available. Figure 7 shows a fragment of this language.
All the information that the client software must understand is contained in the start tags for each object: i.e. the client programme need understand only the name and attributes in the start tag. The information between the start and end tags, is either subsidiary objects or free-form text intended for a human reader. This makes the parsing application very simple. The start-tags for any objects in the language may contain the attribute "uri" indicating that something downloadable is associated with the object. The value of the attribute is a URI, typically pointing to a CGI script at a data centre. The "uri" attributes of data-product objects contain all the information necessary to fetch just the selected data; e.g. the URI for a catalogue server typically has position and search-radius arguments filled in by the portal. The client software is not expected to parse or modify the "uri" attributes. Objects other than data-products can also contain URIs: these are assumed to point to human-readable descriptions that can be rendered by a normal web-browser.
Images in data-products are assumed to be FITS, to include a WCS and to be entirely self-describing. For these, we add no metadata in the coverage report.
Catalogue extracts in data-products are assumed to be in tab-separated-value format (TSV), as in the CADC/ESO convention, and we have to add metadata to allow the client software to interpret the columns. The "catalogue-key" attribute in a data-product tag states the column numbers for certain metadata that our browser can use: RA and declination, object classification, and information about the object's size and shape, all of which are used when plotting the catalogue as an overlay on an image display. If the catalogue key is incomplete but states the position columns, the client can plot the catalogue with reduced function. If the catalogue key is missing, the client can display the catalogue as a table but cannot plot it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}